
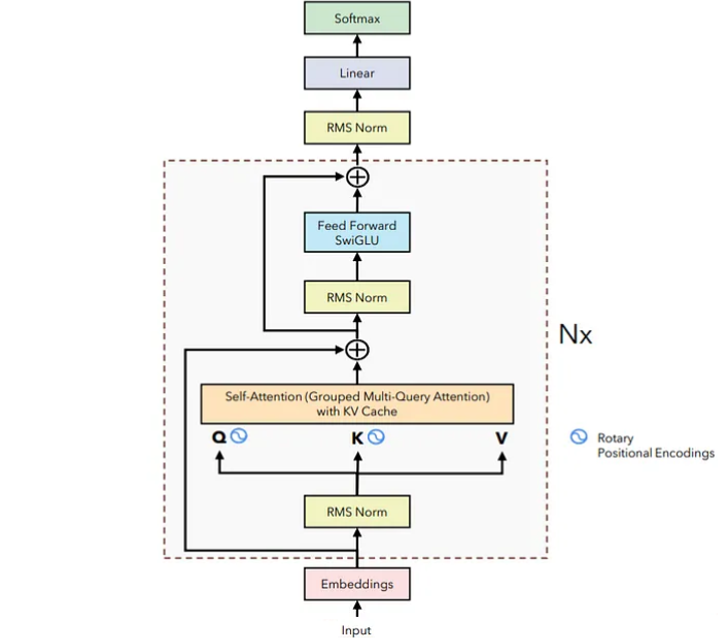
如果前面已经了解过transformer,那么学习llama就顺理成章了一些,llama采用Decoder-only 架构,也就是transformer架构的右侧部分,并结合前人工作做了一些改进,咱们直接来看看整体差异:
一、RoPE (旋转位置编码)
1. 为什么我们需要 RoPE?
在传统的 Transformer 中,Self-Attention 机制本身是置换不变(Permutation Invariant)的。也就是说,如果不加位置编码,模型无法区分 "我爱你" 和 "你爱我"。早期的解决方案(如原始 Transformer 论文)是给每个词加上一个绝对位置向量。但这存在两个问题:
缺乏相对位置感知:模型需要费力地从绝对位置中推导相对距离。
外推能力差:如果训练时最长序列是 512,推理时遇到 1024 的长度,模型往往表现不佳。
RoPE 的核心目标:设计一种编码方式,使得Attention计算的结果天然地、仅依赖于词与词之间的相对距离,从而同时获得更好的泛化能力和长度外推性。。
2. 图解 RoPE:将“位置”转化为“旋转”
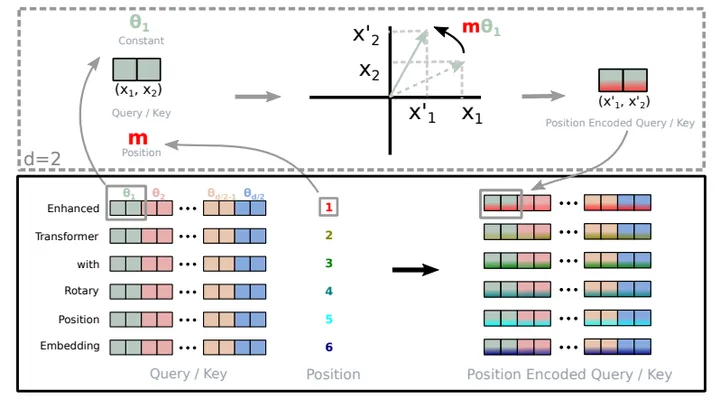
🟢 上半部分:核心几何原理
想象我们在一个二维平面上(对应 embedding 维度),有一个向量,代表某个词的 Query 或 Key 的一部分。
位置即角度:每个位置 m 被映射为一个旋转角度 mθ(图中的 θ1, θ2 即由位置决定)。
编码即旋转:一个词的
Query或Key向量(图中灰色向量),会根据其所在位置 m,在二维平面上旋转 mθ 角度,得到新的 Position Encoded Query/Key 向量。直观理解:可以把它想象成一个钟表盘。不同位置的词,其向量就像指针一样,从初始方向(12点方向)开始旋转。位置 1 转 1 个小角度,位置 2 转 2 倍的角度,以此类推。位置信息已经完全蕴含在旋转后的角度中。
🔵 下半部分:多维度的扩展
真实的 Embedding 维度通常是 4096 或更高,不仅仅是 2 维。RoPE 如何处理?
分组旋转:如图所示,RoPE将高维向量成对地划分为多个二维子空间。图中每一行代表一个词(Token),每一列代表一个维度。颜色相同的两个格子(如浅红与深红)即组成一个二维组。
不同频率:关键来了!不同颜色的组(红、绿、蓝…)使用不同的旋转速度(频率)。这通过为每组设置不同的基础旋转角度
θ来实现(通常按指数衰减设置)。这类似于傅里叶变换,让模型能够用不同“转速”的旋转组合来捕捉从短程到长程的复杂依赖模式。
最终,一个高维的词向量,其每一对维度都根据词的位置进行了独立的旋转,从而将完整的位置信息编织进向量的各个角落。
3. 数学魔法:为什么旋转能表示相对位置?
这是 RoPE 最精妙的地方。旋转操作有一个美妙的数学性质:两个向量旋转后再做点积,其结果只与它们原始的夹角和相对旋转角度有关。让我们形式化地看一下:
设词在位置的查询向量为,在位置的键向量为。经过RoPE编码后,它们分别被旋转了和角度。当我们计算Attention分数(即点积)时,根据复数乘法或旋转矩阵的性质,它等价于将其中一个向量(比如 )反向旋转角度后,再与做点积。
用公式简化表示:
这样一来,绝对位置 m和 n消失了,最终只剩下它们的差值 (n-m),即相对距离。 这意味着,在Attention计算时,模型无需任何额外学习,就能直接感知词与词之间的相对位置关系。
平移不变形(QK乘积只与QK的相对位置有关,与他们的绝对位置无关)
理解了原理,代码便一目了然。RoPE的实现本质是应用一系列二维旋转。
1. 几何操作 vs. 数值叠加:对语义空间的干扰不同
绝对位置编码(Additive):就像一个“拼贴”过程。将代表词义的向量
V_word和代表位置的向量V_pos直接相加,得到V_final = V_word + V_pos。问题:即使
V_pos设计得与大部分V_word正交,加法操作在几何上相当于将词向量“推”到了语义空间中的一个新点。这会不可避免地改变词向量的原始方向和长度。模型必须从这个“被污染”的表示中,费力地分离出纯粹的语义信息和位置信息。这确实引入了噪声或干扰。
旋转位置编码(Multiplicative/Rotative):就像一个“旋转”过程。它在词向量所在的同一高维空间内,通过一个保持长度不变的旋转变换来编码位置。
优势:旋转不改变向量的模长(即“强度”或“能量”),只改变其方向。这意味着,词向量本身的“语义强度”被完整保留。位置信息被编码在方向的变化规律中。这是一种更“优雅”的干扰,因为它严格遵守了几何规则。
2. 内积(点积)的性质:相对位置的内生性
这是 RoPE 最精妙的数学特性,也印证了你的“更纯粹”说。
绝对位置编码:计算 Attention 分数时,
<q_m, k_n> = <(q + p_m), (k + p_n)>。展开后包含p_m和p_n的交叉项,模型需要学习这些复杂的交互模式来推断相对位置。旋转位置编码:正如我们之前推导的,经过旋转后,
<Rotate(q, mθ), Rotate(k, nθ)> = <q, Rotate(k, (n-m)θ)>。这个等式的成立,完全依赖于旋转操作在线性代数中“保内积”和“可交换”的优良性质。相对位置
(n-m)被直接、干净地提取出来,并作用于原始的键向量k。这个过程没有引入任何新的、与语义无关的向量或复杂的交互项。相对位置感知能力是旋转变换的自然产物,而不是模型从噪声数据中学到的模式。这使它从原理上就更加“纯粹”和高效。
3. 信息注入方式:正交与融合
绝对位置编码:试图将位置信息作为一个独立的、正交的维度“贴”到语义向量上。但这在实际高维空间和复杂训练中很难完美实现,容易产生“信息粘连”。
旋转位置编码:它将位置信息编织进语义向量的每一个维度对中。它不是添加一个新维度,而是改变现有维度之间的关系(即相位差)。这就像调制无线电波:载波(语义信息)的振幅不变,而是通过改变其相位(位置信息)来编码信号。这是一种更深层次的“融合”,而非“叠加”。
二、RMSNorm
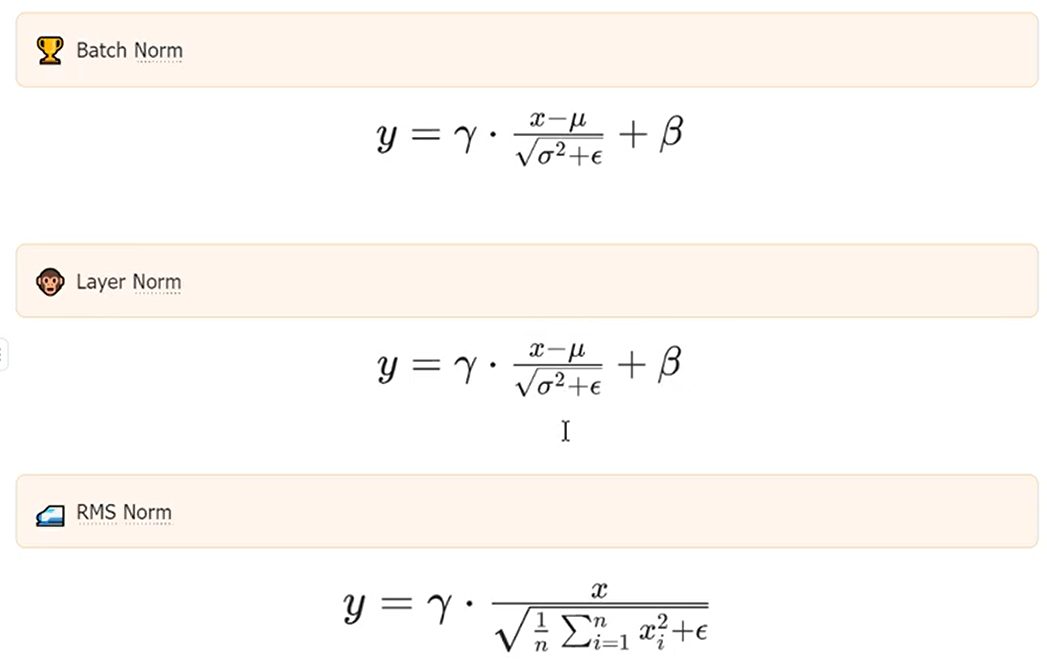
三、KV Cache与GQA (分组查询注意力)
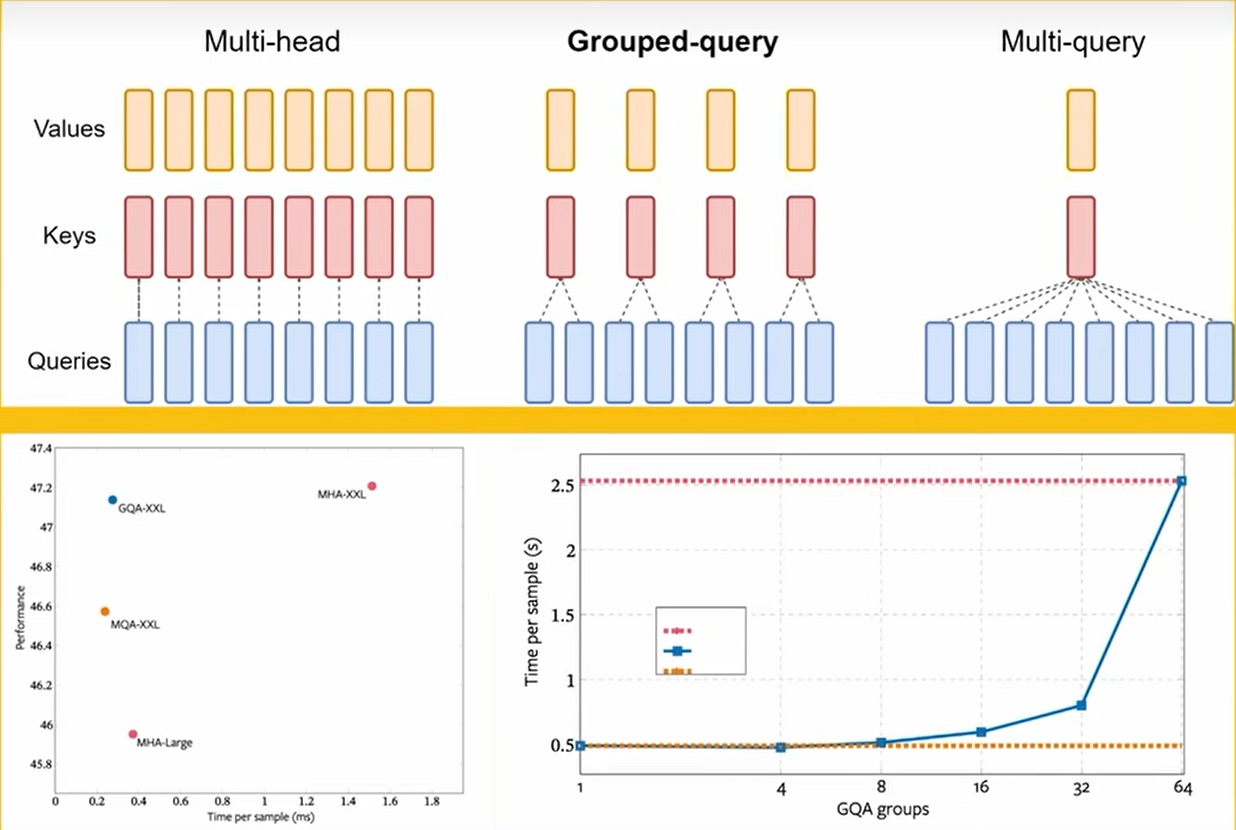
(需要再具体,手绘推导)
四、SwiGLU激活函数
什么是激活函数?
如果把神经网络中的一个神经元想象成一个简单的“加工站”:它接收输入的数字,进行一些加减乘除的计算,然后输出结果。但如果每个加工站都只做这种线性计算,那么无论堆叠多少层,整个网络也只能处理最简单、最直来直去的模式。激活函数,就是这个加工站里一个关键的“魔法开关”。它的作用是对计算出的结果进行一次非线性的转换——比如把负数变成零、把数值压缩到某个范围内,或者根据结果本身动态调整输出。正是这一步“魔法操作”,让神经元能够学习到数据中各种复杂的弯曲、转折与关联,从而赋予人工智能模型理解图像、语言和世界深层规律的能力。没有它,AI的大脑就如同只能画直线的尺子,无法描绘出丰富多彩的现实世界。
SwiGLU激活函数又是什么?
在了解SwiGLU之前,需要先了解Swish函数(也叫SiLU),以及GLU(Gated Linear Unit,门控线性单元)。
Swish函数
(通常),其中 σ 是 sigmoid 函数(),故一般而言
GLU
GLU是一种门控结构,它把“线性变换”这一步,一口气做成两份(用两套不同的权重W和V):一份变换(W*x)负责生成要传递的“内容”。另一份变换(V*x)经过一个Sigmoid函数,生成一个0到1之间的“门控信号”。然后,它将“内容”和“门控信号”逐元素相乘。公式如下:
(其中 ⊗是逐元素乘法,σ是Sigmoid函数)
公式看起来有些复杂,咱们直接看一个例子,假设我们正在处理一个单词的向量表示,并且为了计算简单,我们使用一个2维的输入向量。
第1步:准备输入
我们的输入向量 x代表一个单词的特征, ;
第2步:定义权重矩阵
GLU需要两个不同的权重矩阵 W和 V。为了简化,我们假设它们是2×2的小矩阵,在实际的神经网络中,这些权重是通过训练学习得到的。
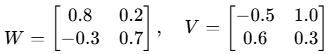
第3步:计算内容部分 (Wx)
专家A对输入进行处理:
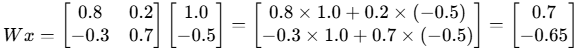
这就是经过专家A加工后的"原始内容"。
第4步:计算门控信号 (σ(Vx))
专家B也对同一个输入进行处理:
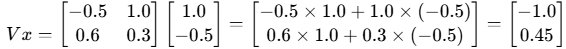
然后将这个结果通过Sigmoid函数(σ),将每个值压缩到0到1之间:
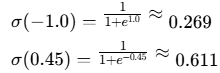
所以门控信号为:
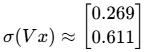
第5步:逐元素相乘(门控)
现在我们将内容部分与门控信号逐元素相乘:
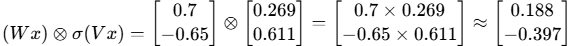
最终结果分析
我们的GLU输出是 [0.188, -0.397]。看看发生了什么:
第一个维度:原始内容值是0.7,门控信号是0.269,这意味着只保留了约26.9%的信息。可能是因为专家B认为这个特征在当前上下文中不太重要。
第二个维度:原始内容值是-0.65,门控信号是0.611,这意味着保留了约61.1%的信息,而且保持了负号。负值在神经网络中同样传递重要信息。
基于上述内容,咱们可以回到swiGLU来, ,相当于就是把原来门控当中的 sigmoid 函数替换成 swish 函数,即上述第4步:计算门控信号 σ(Vx)替换成 swish(Vx),其他步骤不会有任何变化,这里计算比较简单就不展开赘述了。