
transformer 模型架构图示
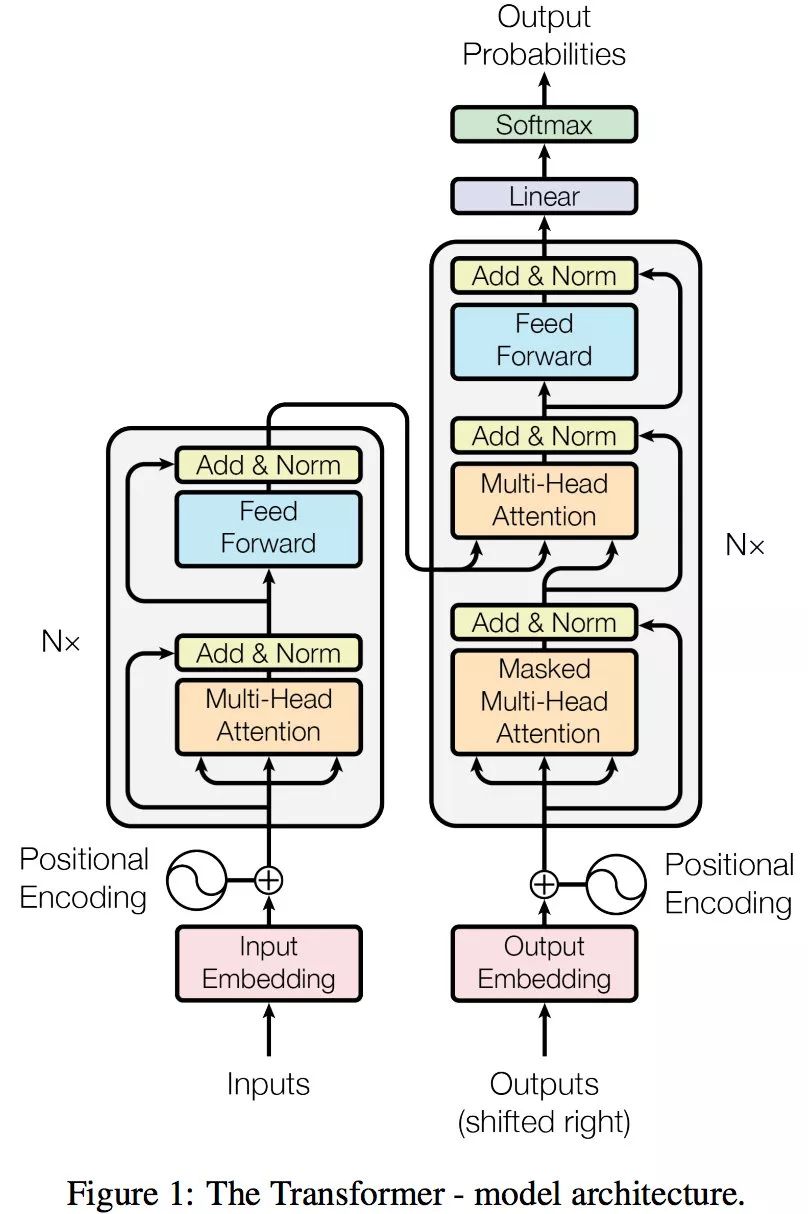
一、transformer的子模块划分
1.1、注意力机制
1.1.1、缩放点积注意力机制(Scaled Dot-Product Attention)
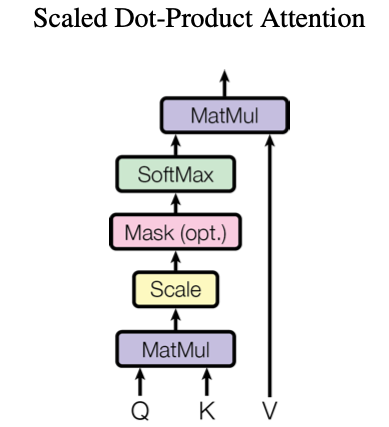
Q(Query): 用于查询的向量矩阵。
K(Key): 表示键的向量矩阵,用于与查询匹配。
V(Value): 值矩阵,注意力权重最终会作用在该矩阵上。
dk: 键或查询向量的维度。
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
缩放点积注意力计算。
参数:
Q: 查询矩阵 (batch_size, seq_len_q, embed_size)
K: 键矩阵 (batch_size, seq_len_k, embed_size)
V: 值矩阵 (batch_size, seq_len_v, embed_size)
mask: 掩码矩阵,用于屏蔽不应该关注的位置 (可选)
返回:
output: 注意力加权后的输出矩阵
attention_weights: 注意力权重矩阵
"""
embed_size = Q.size(-1) # embed_size
# 计算点积并进行缩放
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(embed_size)
# 如果提供了掩码矩阵,则将掩码对应位置的分数设为 -inf
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# 对缩放后的分数应用 Softmax 函数,得到注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 加权求和,计算输出
output = torch.matmul(attention_weights, V)
return output, attention_weights
def main():
# 设置随机种子以便复现结果
torch.manual_seed(42)
# 创建测试数据
batch_size = 2
seq_len = 3 # 假设我们有3个词
embed_size = 4 # 每个词用4维向量表示
# Q, K, V 在自注意力中通常相同或来自同一输入
Q = torch.randn(batch_size, seq_len, embed_size)
K = torch.randn(batch_size, seq_len, embed_size)
V = torch.randn(batch_size, seq_len, embed_size)
output, attention_weights = scaled_dot_product_attention(Q, K, V)
print("attention_weights is",attention_weights,"\n")
print("output is",output,"\n")
if __name__ == "__main__":
main()attention_weights is tensor([[[0.2746, 0.2220, 0.5034],
[0.4423, 0.3890, 0.1687],
[0.2303, 0.5218, 0.2479]],
[[0.1818, 0.0759, 0.7424],
[0.2404, 0.4599, 0.2997],
[0.3681, 0.2300, 0.4019]]])
output is tensor([[[-0.2196, 0.3126, -0.0202, -0.3293],
[ 0.0989, 0.1511, -0.1175, -0.2992],
[ 0.1140, 0.3381, 0.3332, -0.1965]],
[[-0.2581, 0.2895, 2.8606, 1.0711],
[-0.5805, 0.2681, 1.1562, 0.7658],
[-0.4114, 0.3388, 1.3747, 0.8071]]])
可视化理解:
注意力权重(第一个样本):
Query1 → Key1: 27.46% Key2: 22.20% Key3: 50.34%
Query2 → Key1: 44.23% Key2: 38.90% Key3: 16.87%
Query3 → Key1: 23.03% Key2: 52.18% Key3: 24.79%
输出(第一个样本的新表示):
新词1 = 27.46%×原始词1 + 22.20%×原始词2 + 50.34%×原始词3
新词2 = 44.23%×原始词1 + 38.90%×原始词2 + 16.87%×原始词3
新词3 = 23.03%×原始词1 + 52.18%×原始词2 + 24.79%×原始词3
原始值向量V (3×4):
词1: [v11, v12, v13, v14] ← 权重0.2746
词2: [v21, v22, v23, v24] ← 权重0.2220
词3: [v31, v32, v33, v34] ← 权重0.5034
↓
加权平均(每个维度分别加权)
↓
词1的新向量: [加权v11, 加权v12, 加权v13, 加权v14]
对第一个词的每个维度:
新v11 = 0.2746×v11 + 0.2220×v21 + 0.5034×v31
新v12 = 0.2746×v12 + 0.2220×v22 + 0.5034×v32
新v13 = 0.2746×v13 + 0.2220×v23 + 0.5034×v33
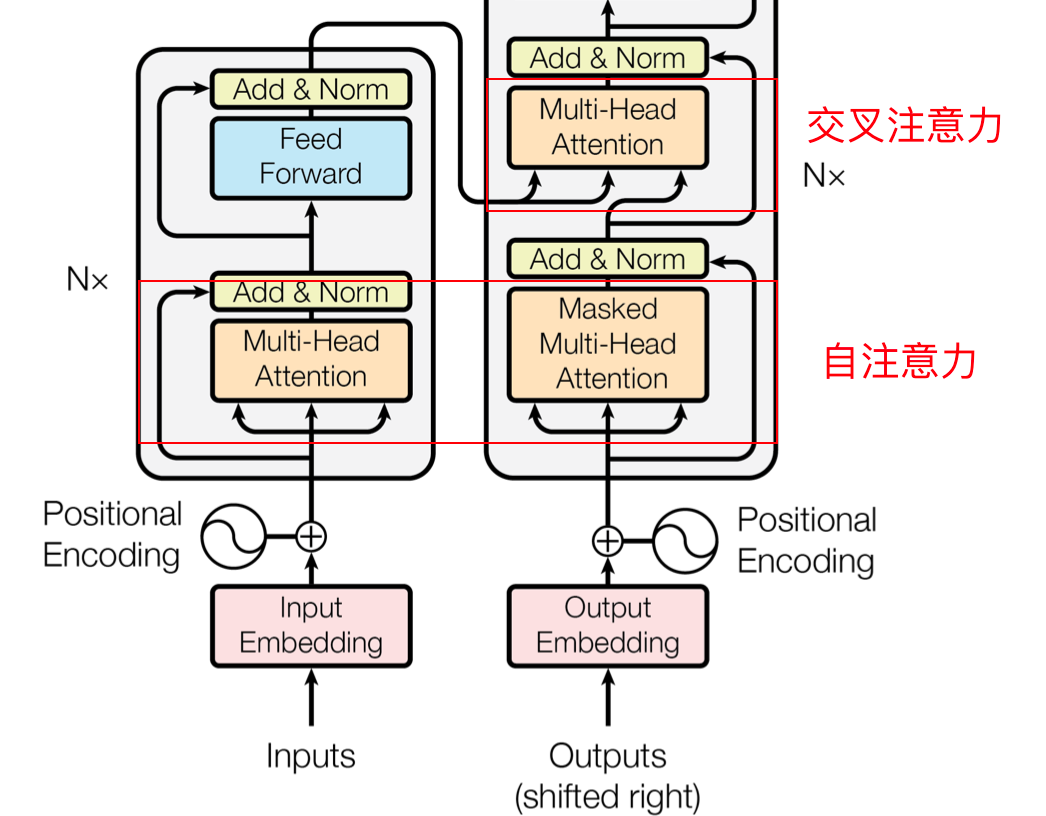
新v14 = 0.2746×v14 + 0.2220×v24 + 0.5034×v341.1.2、单头注意力机制(Single-Head Attention)
在transformer当中,我们可以把注意力机制区分为自注意力和交叉注意力机制,如图所示。显而易见,自注意力机制当中的q,k,v均来自自己,也就是 q=k=v,而交叉注意力机制的 q≠k=v,这就是二者的差异
class Attention(nn.Module):
def __init__(self, embed_size):
"""
单头注意力机制。
参数:
embed_size: 输入序列(Inputs)的嵌入(Input Embedding)维度,也是论文中所提到的d_model。
"""
super(Attention, self).__init__()
self.embed_size = embed_size
# 定义线性层,用于生成查询、键和值矩阵
self.w_q = nn.Linear(embed_size, embed_size)
self.w_k = nn.Linear(embed_size, embed_size)
self.w_v = nn.Linear(embed_size, embed_size)
def forward(self, q, k, v, mask=None):
"""
前向传播函数。
参数:
q: 查询矩阵 (batch_size, seq_len_q, embed_size)
k: 键矩阵 (batch_size, seq_len_k, embed_size)
v: 值矩阵 (batch_size, seq_len_v, embed_size)
若此处的q=k=v,则为自注意力运算;
若此处的q≠k=v,则为交叉注意力运算
mask: 掩码矩阵,用于屏蔽不应关注的位置 (batch_size, seq_len_q, seq_len_k)
返回:
out: 注意力加权后的输出
attention_weights: 注意力权重矩阵
"""
# 将输入序列通过线性变换生成 Q, K, V
Q = self.w_q(q) # (batch_size, seq_len_q, embed_size)
K = self.w_k(k) # (batch_size, seq_len_k, embed_size)
V = self.w_v(v) # (batch_size, seq_len_v, embed_size)
# 使用缩放点积注意力函数计算输出和权重
out, attention_weights = scaled_dot_product_attention(Q, K, V, mask)
return out, attention_weights1.1.3、**多头注意力机制(Multi-Head Attention)
假设我们有 h 个头,每个头拥有独立的线性变换矩阵,,(分别作用于查询、键和值的映射),每个头的计算如下:
这些头的输出将沿最后一维拼接(Concat),并通过线性变换矩阵 WO 映射回原始嵌入维度(embed_size):
h:注意力头的数量。
WO:拼接后所通过的线性变换矩阵,用于将多头的输出映射回原始维度。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
"""
多头注意力机制:每个头单独定义线性层。
参数:
embed_size: 输入序列的嵌入维度。
num_heads: 注意力头的数量。
"""
super(MultiHeadAttention, self).__init__()
assert embed_size % num_heads == 0, "embed_size 必须能被 num_heads 整除。"
self.embed_size = embed_size
self.num_heads = num_heads
self.head_dim = embed_size // num_heads # 每个头的维度
# 为每个头单独定义 Q, K, V 的线性层
self.w_q = nn.ModuleList([nn.Linear(embed_size, self.head_dim) for _ in range(num_heads)])
self.w_k = nn.ModuleList([nn.Linear(embed_size, self.head_dim) for _ in range(num_heads)])
self.w_v = nn.ModuleList([nn.Linear(embed_size, self.head_dim) for _ in range(num_heads)])
# 输出线性层,将多头拼接后的输出映射回 embed_size
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, q, k, v, mask=None):
"""
前向传播函数。
参数:
q: 查询矩阵 (batch_size, seq_len_q, embed_size)
k: 键矩阵 (batch_size, seq_len_k, embed_size)
v: 值矩阵 (batch_size, seq_len_v, embed_size)
mask: 掩码矩阵 (batch_size, seq_len_q, seq_len_k)
返回:
out: 注意力加权后的输出
attention_weights: 注意力权重矩阵
"""
batch_size = q.shape[0]
multi_head_outputs = []
# 针对每个头独立计算 Q, K, V,并执行缩放点积注意力
for i in range(self.num_heads):
Q = self.w_q[i](q) # (batch_size, seq_len_q, head_dim)
K = self.w_k[i](k) # (batch_size, seq_len_k, head_dim)
V = self.w_v[i](v) # (batch_size, seq_len_v, head_dim)
# 执行缩放点积注意力
scaled_attention, _ = scaled_dot_product_attention(Q, K, V, mask)
multi_head_outputs.append(scaled_attention)
# 将所有头的输出拼接起来
concat_out = torch.cat(multi_head_outputs, dim=-1) # (batch_size, seq_len_q, embed_size)
# 通过输出线性层
out = self.fc_out(concat_out) # (batch_size, seq_len_q, embed_size)
return out
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
缩放点积注意力计算。
参数:
Q: 查询矩阵 (batch_size, seq_len_q, head_dim)
K: 键矩阵 (batch_size, seq_len_k, head_dim)
V: 值矩阵 (batch_size, seq_len_v, head_dim)
mask: 掩码矩阵 (batch_size, seq_len_q, seq_len_k)
返回:
output: 注意力加权后的输出矩阵
attention_weights: 注意力权重矩阵
"""
...(使用之前的缩放点积注意力函数,区别在于修改了注释里面的 shape)
return output, attention_weights以上代码在逻辑已经没问题,且易于理解,但计算起来却极慢(特别有for循环的情况下),故还可以进一步优化,这里同时提供了可测试数据以方便理解:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h):
"""
多头注意力机制:每个头单独定义线性层。
参数:
d_model: 输入序列的嵌入维度。
h: 注意力头的数量。
"""
super(MultiHeadAttention, self).__init__()
assert d_model % h == 0, "d_model 必须能被 h 整除。"
self.d_model = d_model
self.h = h
# “共享”的 Q, K, V 线性层
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# 输出线性层,将多头拼接后的输出映射回 d_model
self.fc_out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
"""
前向传播函数。
参数:
q: 查询矩阵 (batch_size, seq_len_q, d_model)
k: 键矩阵 (batch_size, seq_len_k, d_model)
v: 值矩阵 (batch_size, seq_len_v, d_model)
mask: 掩码矩阵 (batch_size, 1, seq_len_q, seq_len_k)
返回:
out: 注意力加权后的输出
attention_weights: 注意力权重矩阵
"""
batch_size = q.size(0)
# 获取查询和键值的序列长度
seq_len_q = q.size(1)
seq_len_k = k.size(1)
# 将线性变换后的“共享”矩阵拆分为多头,调整维度为 (batch_size, h, seq_len, d_k)
# d_k 就是每个注意力头的维度
Q = self.w_q(q).view(batch_size, seq_len_q, self.h, -1).transpose(1, 2)
K = self.w_k(k).view(batch_size, seq_len_k, self.h, -1).transpose(1, 2)
V = self.w_v(v).view(batch_size, seq_len_k, self.h, -1).transpose(1, 2)
# 执行缩放点积注意力
scaled_attention, _ = scaled_dot_product_attention(Q, K, V, mask)
# 合并多头并还原为 (batch_size, seq_len_q, d_model)
concat_out = scaled_attention.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 通过输出线性层
out = self.fc_out(concat_out) # (batch_size, seq_len_q, d_model)
return out
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
缩放点积注意力计算。
参数:
Q: 查询矩阵 (batch_size, num_heads, seq_len_q, d_k)
K: 键矩阵 (batch_size, num_heads, seq_len_k, d_k)
V: 值矩阵 (batch_size, num_heads, seq_len_v, d_v)
mask: 掩码矩阵 (batch_size, 1, seq_len_q, seq_len_k) 或 (1, 1, seq_len_q, seq_len_k) 或 (batch_size, h, seq_len_q, seq_len_k)
返回:
output: 注意力加权后的输出矩阵
attention_weights: 注意力权重矩阵
"""
d_k = Q.size(-1) # d_k
# 计算点积并进行缩放
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
# 如果提供了掩码矩阵,则将掩码对应位置的分数设为 -inf
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# 对缩放后的分数应用 Softmax 函数,得到注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 加权求和,计算输出
output = torch.matmul(attention_weights, V)
return output, attention_weights
def main():
# 设置随机种子以便复现
torch.manual_seed(42)
# 定义参数
batch_size = 2
seq_len_q = 5 # 查询序列长度
seq_len_kv = 7 # 键值序列长度
d_model = 512 # 嵌入维度
num_heads = 8 # 注意力头数量
# 创建随机输入
q = torch.randn(batch_size, seq_len_q, d_model)
k = torch.randn(batch_size, seq_len_kv, d_model)
v = torch.randn(batch_size, seq_len_kv, d_model)
# 创建多头注意力层
mha = MultiHeadAttention(d_model, num_heads)
# 带掩码的前向传播
mask = torch.tril(torch.ones(seq_len_q, seq_len_kv)).unsqueeze(0).unsqueeze(0)
output_masked, attention_weights_masked = mha(q, k, v, mask=mask)
# 输出信息
print(f"\noutput_masked=:", output_masked.data)
print(f"\noutput_weights_masked=:", attention_weights_masked.data)
if __name__ == "__main__":
main()1.2、*前馈神经网络(FFN)
这里的FFN(Feed-Forward Network)其实就是两层MLP(多层感知机), 针对每个位置 i 的计算为:
xi∈Rdmodel 表示第 i 个位置的输入向量。
W1∈Rdmodel ×dff 和 W2∈Rdff×dmodel 是两个线性变换的权重矩阵。
b1∈Rdff 和 b2∈Rdmodel 是对应的偏置向量。
max(0, ⋅) 是 ReLU 激活函数,用于引入非线性。
import torch
import torch.nn as nn
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
"""
位置前馈网络。
参数:
d_model: 输入和输出向量的维度
d_ff: FFN 隐藏层的维度,或者说中间层
dropout: 随机失活率(Dropout),即随机屏蔽部分神经元的输出,用于防止过拟合
(实际上论文并没有确切地提到在这个模块使用 dropout,所以注释)
"""
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff) # 第一个线性层
self.w_2 = nn.Linear(d_ff, d_model) # 第二个线性层
#self.dropout = nn.Dropout(dropout) # Dropout 层
def forward(self, x):
# 先经过第一个线性层和 ReLU,然后经过第二个线性层
return self.w_2(self.w_1(x).relu()) #self.w_2(self.dropout(self.w_1(x).relu()))1.3、*残差连接和层归一化(Add & Norm)
残差连接是一种跳跃连接(Skip Connection),它将层的输入直接加到输出上,对应的公式如下:
这种连接方式能有效缓解深层神经网络的梯度消失问题。比较通俗的理解是,随着神经网络深度的增加,浅层的信息逐渐被淡化,此时咱们通过一个跳跃连接,直接把浅层的信息桥接到深层,则可以弥补淡化甚至缺失的信息。
import torch
import torch.nn as nn
class ResidualConnection(nn.Module):
def __init__(self, dropout=0.1):
"""
残差连接,用于在每个子层后添加残差连接和 Dropout。
参数:
dropout: Dropout 概率,用于在残差连接前应用于子层输出,防止过拟合。
"""
super(ResidualConnection, self).__init__()
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, sublayer):
"""
前向传播函数。
参数:
x: 残差连接的输入张量,形状为 (batch_size, seq_len, d_model)。
sublayer: 子层模块的函数,多头注意力或前馈网络。
返回:
经过残差连接和 Dropout 处理后的张量,形状为 (batch_size, seq_len, d_model)。
"""
# 将子层输出应用 dropout,然后与输入相加(参见论文 5.4 的表述或者本文「呈现」部分)
return x + self.dropout(sublayer(x))LayerNorm 的计算过程
假设输入向量为 x=(x1,x2,…,xd), LayerNorm 的计算步骤如下:
计算均值和方差: 对输入的所有特征求均值 μ 和方差 σ2:
,
归一化公式: 将输入特征 进行归一化:
其中, ϵ 是一个很小的常数(比如 1e-9),用于防止除以零的情况。
引入可学习参数: 归一化后的输出乘以 γ 并加上 β, 公式如下:
其中 γ 和 β 是可学习的参数,用于进一步调整归一化后的输出。
class LayerNorm(nn.Module):
def __init__(self, feature_size, epsilon=1e-9):
"""
层归一化,用于对最后一个维度进行归一化。
参数:
feature_size: 输入特征的维度大小,即归一化的特征维度。
epsilon: 防止除零的小常数。
"""
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(feature_size)) # 可学习缩放参数,初始值为 1
self.beta = nn.Parameter(torch.zeros(feature_size)) # 可学习偏移参数,初始值为 0
self.epsilon = epsilon
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.epsilon) + self.betaAdd & Norm
操作步骤:
残差连接:将输入直接与子层的输出相加。
层归一化:对相加后的结果进行归一化。
公式如下,其中,SubLayer(x) 表示 Transformer 中的某个子层(如自注意力层或前馈网络层)的输出,因此,Add & Norm 操作也被称为“子层连接”,它在每个子层的输出上应用残差和归一化。
class SublayerConnection(nn.Module):
def __init__(self, feature_size, dropout=0.1, epsilon=1e-9):
"""
子层连接,包括残差连接和层归一化,应用于 Transformer 的每个子层。
参数:
feature_size: 输入特征的维度大小,即归一化的特征维度。
dropout: 残差连接中的 Dropout 概率。
epsilon: 防止除零的小常数。
"""
super(SublayerConnection, self).__init__()
self.residual = ResidualConnection(dropout) # 使用 ResidualConnection 进行残差连接
self.norm = LayerNorm(feature_size, epsilon) # 层归一化
def forward(self, x, sublayer):
# 将子层输出应用 dropout 后经过残差连接后再进行归一化
return self.norm(self.residual(x, sublayer))
# 或者直接在 AddNorm 里面实现残差连接
class SublayerConnection(nn.Module):
"""
子层连接的另一种实现方式,残差连接直接在该模块中实现。
参数:
feature_size: 输入特征的维度大小,即归一化的特征维度。
dropout: 残差连接中的 Dropout 概率。
epsilon: 防止除零的小常数。
"""
def __init__(self, feature_size, dropout=0.1, epsilon=1e-9):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(feature_size, epsilon)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, sublayer):
# 将子层输出应用 dropout 后经过残差连接后再进行归一化
return self.norm(x + self.dropout(sublayer(x)))1.4、嵌入(Embeddings)和*位置编码(Positional Encoding)
嵌入层
import torch
import torch.nn as nn
import math
class Embeddings(nn.Module):
"""
嵌入,将 token ID 转换为固定维度的嵌入向量,并进行缩放。
参数:
vocab_size: 词汇表大小。
d_model: 嵌入向量的维度。
"""
def __init__(self, vocab_size, d_model):
super(Embeddings, self).__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.scale_factor = math.sqrt(d_model)
def forward(self, x):
"""
前向传播函数。
参数:
x: 输入张量,形状为 (batch_size, seq_len),其中每个元素是 token ID。
返回:
缩放后的嵌入向量,形状为 (batch_size, seq_len, d_model)。
"""
return self.embed(x) * self.scale_factor位置编码
在原始论文中,Transformer 使用的是固定位置编码(Positional Encoding),其公式如下:
其中:
pos 表示位置索引(Position)。
i 表示维度索引。
dmodel 是嵌入向量的维度。
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
位置编码,为输入序列中的每个位置添加唯一的位置表示,以引入位置信息。
参数:
d_model: 嵌入维度,即每个位置的编码向量的维度。
dropout: 位置编码后应用的 Dropout 概率。
max_len: 位置编码的最大长度,适应不同长度的输入序列。
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 正如论文 5.4 节所提到的,需要将 Dropout 应用在 embedding 和 positional encoding 相加的时候
# 创建位置编码矩阵,形状为 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1) # 位置索引 (max_len, 1)
# 计算每个维度对应的频率
div_term = torch.exp(
torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)
)
# 将位置和频率结合,计算 sin 和 cos
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度
# 增加一个维度,方便后续与输入相加,形状变为 (1, max_len, d_model)
pe = pe.unsqueeze(0)
# 将位置编码注册为模型的缓冲区,不作为参数更新
self.register_buffer('pe', pe)
def forward(self, x):
"""
前向传播函数。
参数:
x: 输入序列的嵌入向量,形状为 (batch_size, seq_len, d_model)。
返回:
加入位置编码和 Dropout 后的嵌入向量,形状为 (batch_size, seq_len, d_model)。
"""
# 取出与输入序列长度相同的部分位置编码,并与输入相加
x = x + self.pe[:, :x.size(1), :]
# 应用 dropout
return self.dropout(x)编码器输入
class SourceEmbedding(nn.Module):
def __init__(self, src_vocab_size, d_model, dropout=0.1):
"""
源序列嵌入,将输入的 token 序列转换为嵌入向量并添加位置编码。
参数:
src_vocab_size: 源语言词汇表的大小
d_model: 嵌入向量的维度
dropout: 在位置编码后应用的 Dropout 概率
"""
super(SourceEmbedding, self).__init__()
self.embed = Embeddings(src_vocab_size, d_model) # 词嵌入层
self.positional_encoding = PositionalEncoding(d_model, dropout) # 位置编码层
def forward(self, x):
"""
前向传播函数。
参数:
x: 源语言序列的输入张量,形状为 (batch_size, seq_len_src),其中每个元素是 token ID。
返回:
添加位置编码后的嵌入向量,形状为 (batch_size, seq_len_src, d_model)。
"""
x = self.embed(x) # 生成词嵌入 (batch_size, seq_len_src, d_model)
return self.positional_encoding(x) # 加入位置编码
1.5、Softmax
Softmax 是一种常用的激活函数,能够将任意实数向量转换为概率分布,确保每个元素的取值范围在 [0, 1] 之间,并且所有元素的和为 1。其数学定义如下:
xi 表示输入向量中的第 i 个元素。
Softmax(xi) 表示输入 xi 转换后的概率。
可以把 Softmax 看作一种归一化的指数变换。相比于简单的比例归一化 , Softmax 通过指数变换放大数值间的差异,让较大的值对应更高的概率,同时避免了负值和数值过小的问题。
import torch
import torch.nn as nn
def softmax(x):
exp_x = torch.exp(x)
sum_exp_x = torch.sum(exp_x, dim=-1, keepdim=True)
return exp_x / sum_exp_x
# 测试向量
x = torch.tensor([1.0, 2.0, 3.0])
# 根据公式实现的 Softmax
result = softmax(x)
# 使用 nn.Softmax
softmax = nn.Softmax(dim=-1)
nn_result = softmax(x)
print("根据公式实现的 Softmax 结果:", result)
print("nn.Softmax 的结果:", nn_result)二、编码器与解码器构建
2.1、编码器层 (Encoder Layer)
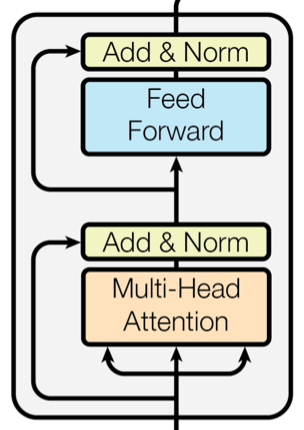
class EncoderLayer(nn.Module):
def __init__(self, d_model, h, d_ff, dropout):
"""
编码器层。
参数:
d_model: 嵌入维度
h: 多头注意力的头数
d_ff: 前馈神经网络的隐藏层维度
dropout: Dropout 概率
"""
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, h) # 多头自注意力(Multi-Head Self-Attention)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout) # 前馈神经网络
# 定义两个子层连接,分别用于多头自注意力和前馈神经网络(对应模型架构图中的两个残差连接)
self.sublayers = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(2)])
self.d_model = d_model
def forward(self, x, src_mask):
"""
前向传播函数。
参数:
x: 输入张量,形状为 (batch_size, seq_len, d_model)。
src_mask: 源序列掩码,用于自注意力。
返回:
编码器层的输出,形状为 (batch_size, seq_len, d_model)。
"""
x = self.sublayers[0](x, lambda x: self.self_attn(x, x, x, src_mask)) # 自注意力子层
x = self.sublayers[1](x, self.feed_forward) # 前馈子层
return x2.2、解码器层(Decoder Layer)
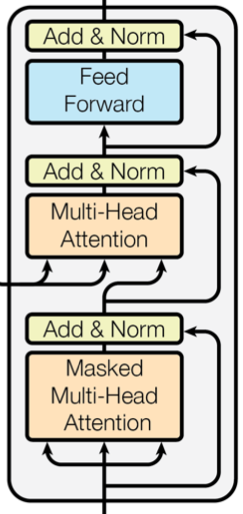
class DecoderLayer(nn.Module):
def __init__(self, d_model, h, d_ff, dropout):
"""
解码器层。
参数:
d_model: 嵌入维度
h: 多头注意力的头数
d_ff: 前馈神经网络的隐藏层维度
dropout: Dropout 概率
"""
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, h) # 掩码多头自注意力(Masked Multi-Head Self-Attention)
self.cross_attn = MultiHeadAttention(d_model, h) # 多头交叉注意力(Multi-Head Cross-Attention)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout) # 前馈神经网络
# 定义三个子层连接,分别用于掩码多头自注意力、多头交叉注意力和前馈神经网络(对应模型架构图中的三个残差连接)
self.sublayers = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(3)])
self.d_model = d_model
def forward(self, x, memory, src_mask, tgt_mask):
"""
前向传播函数。
参数:
x: 解码器输入 (batch_size, seq_len_tgt, d_model)
memory: 编码器输出 (batch_size, seq_len_src, d_model)
src_mask: 源序列掩码,用于交叉注意力
tgt_mask: 目标序列掩码,用于自注意力
返回:
x: 解码器层的输出
"""
# 第一个子层:掩码多头自注意力(Masked Multi-Head Self-Attention)
x = self.sublayers[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# 第二个子层:交叉多头注意力(Multi-Head Cross-Attention),使用编码器的输出 memory
x = self.sublayers[1](x, lambda x: self.cross_attn(x, memory, memory, src_mask))
# 第三个子层:前馈神经网络
x = self.sublayers[2](x, self.feed_forward)
return x2.3、编码器
class Encoder(nn.Module):
def __init__(self, d_model, N, h, d_ff, dropout=0.1):
"""
编码器,由 N 个 EncoderLayer 堆叠而成。
参数:
d_model: 嵌入维度
N: 编码器层的数量
h: 多头注意力的头数
d_ff: 前馈神经网络的隐藏层维度
dropout: Dropout 概率
"""
super(Encoder, self).__init__()
self.layers = nn.ModuleList([
EncoderLayer(d_model, h, d_ff, dropout) for _ in range(N)
])
self.norm = LayerNorm(d_model) # 最后层归一化
def forward(self, x, mask):
"""
前向传播函数。
参数:
x: 输入张量 (batch_size, seq_len, d_model)
mask: 输入掩码
返回:
编码器的输出
"""
for layer in self.layers:
x = layer(x, mask)
return self.norm(x) # 最后层归一化2.4、解码器
class Decoder(nn.Module):
def __init__(self, d_model, N, h, d_ff, dropout=0.1):
"""
解码器,由 N 个 DecoderLayer 堆叠而成。
参数:
d_model: 嵌入维度
N: 解码器层的数量
h: 多头注意力的头数
d_ff: 前馈神经网络的隐藏层维度
dropout: Dropout 概率
"""
super(Decoder, self).__init__()
self.layers = nn.ModuleList([
DecoderLayer(d_model, h, d_ff, dropout) for _ in range(N)
])
self.norm = LayerNorm(d_model) # 最后层归一化
def forward(self, x, memory, src_mask, tgt_mask):
"""
前向传播函数。
参数:
x: 解码器输入 (batch_size, seq_len_tgt, d_model)
memory: 编码器的输出 (batch_size, seq_len_src, d_model)
src_mask: 用于交叉注意力的源序列掩码
tgt_mask: 用于自注意力的目标序列掩码
返回:
解码器的输出
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x) # 最后层归一化
三、最终模块
输入嵌入和位置编码:
SourceEmbedding:对源序列进行嵌入并添加位置编码。TargetEmbedding:对目标序列进行嵌入并添加位置编码。
多头注意力和前馈网络:
MultiHeadAttention:多头注意力机制。PositionwiseFeedForward:位置前馈网络。
编码器和解码器:
Encoder:由多个EncoderLayer堆叠而成。Decoder:由多个DecoderLayer堆叠而成。
输出层:
fc_out:线性层,将解码器的输出映射到目标词汇表维度。
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, N, h, d_ff, dropout=0.1):
"""
Transformer 模型,由编码器和解码器组成。
参数:
src_vocab_size: 源语言词汇表大小
tgt_vocab_size: 目标语言词汇表大小
d_model: 嵌入维度
N: 编码器和解码器的层数
h: 多头注意力的头数
d_ff: 前馈神经网络的隐藏层维度
dropout: Dropout 概率
"""
super(Transformer, self).__init__()
# 输入嵌入和位置编码,src 对应于编码器输入,tgt 对应于解码器输入
self.src_embedding = SourceEmbedding(src_vocab_size, d_model, dropout)
self.tgt_embedding = TargetEmbedding(tgt_vocab_size, d_model, dropout) # 共享:self.tgt_embedding = self.src_embedding
# 编码器和解码器
self.encoder = Encoder(d_model, N, h, d_ff, dropout)
self.decoder = Decoder(d_model, N, h, d_ff, dropout)
# 输出线性层
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt):
"""
前向传播函数。
参数:
src: 源序列输入 (batch_size, seq_len_src)
tgt: 目标序列输入 (batch_size, seq_len_tgt)
返回:
Transformer 的输出(未经过 Softmax)
"""
# 生成掩码
src_mask = create_padding_mask(src)
tgt_mask = create_decoder_mask(tgt)
# 编码器
enc_output = self.encoder(self.src_embedding(src), src_mask)
# 解码器
dec_output = self.decoder(self.tgt_embedding(tgt), enc_output, src_mask, tgt_mask)
# 输出层
output = self.fc_out(dec_output)
return output实例化与输出
# 定义词汇表大小(根据数据集)
src_vocab_size = 5000 # 源语言词汇表大小
tgt_vocab_size = 5000 # 目标语言词汇表大小
# 使用 Transformer base 参数
d_model = 512 # 嵌入维度
N = 6 # 编码器和解码器的层数
h = 8 # 多头注意力的头数
d_ff = 2048 # 前馈神经网络的隐藏层维度
dropout = 0.1 # Dropout 概率
# 实例化模型
model = Transformer(
src_vocab_size=src_vocab_size,
tgt_vocab_size=tgt_vocab_size,
d_model=d_model,
N=N,
h=h,
d_ff=d_ff,
dropout=dropout
)
# 打印模型架构
print(model)Transformer(
(src_embedding): SourceEmbedding(
(embed): Embeddings(
(embed): Embedding(5000, 512)
)
(positional_encoding): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(tgt_embedding): TargetEmbedding(
(embed): Embeddings(
(embed): Embedding(5000, 512)
)
(positional_encoding): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(encoder): Encoder(
(layers): ModuleList(
(0-5): 6 x EncoderLayer(
(self_attn): MultiHeadAttention(
(w_q): Linear(in_features=512, out_features=512, bias=True)
(w_k): Linear(in_features=512, out_features=512, bias=True)
(w_v): Linear(in_features=512, out_features=512, bias=True)
(fc_out): Linear(in_features=512, out_features=512, bias=True)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=512, out_features=2048, bias=True)
(w_2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayers): ModuleList(
(0-1): 2 x SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(decoder): Decoder(
(layers): ModuleList(
(0-5): 6 x DecoderLayer(
(self_attn): MultiHeadAttention(
(w_q): Linear(in_features=512, out_features=512, bias=True)
(w_k): Linear(in_features=512, out_features=512, bias=True)
(w_v): Linear(in_features=512, out_features=512, bias=True)
(fc_out): Linear(in_features=512, out_features=512, bias=True)
)
(cross_attn): MultiHeadAttention(
(w_q): Linear(in_features=512, out_features=512, bias=True)
(w_k): Linear(in_features=512, out_features=512, bias=True)
(w_v): Linear(in_features=512, out_features=512, bias=True)
(fc_out): Linear(in_features=512, out_features=512, bias=True)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=512, out_features=2048, bias=True)
(w_2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayers): ModuleList(
(0-2): 3 x SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(fc_out): Linear(in_features=512, out_features=5000, bias=True)
)参考材料: